how to build a twitter sentiment analyzer ?
UPDATE: The github repo for twitter sentiment analyzer now contains updated get_twitter_data.py file compatible with Twitter API v1.1. It can be tested by placing appropriate oauth credentials in config.json and running test_twitter_data.py. You can create a new twitter app at https://dev.twitter.com/apps to fetch necessary oauth credentials.
Hi all, It's been almost a year since I last wrote a technical post. A lot of changes have occurred in my life since then, from a Frontend engineer at Yahoo!, I've transformed into a full-time graduate student at UNC-Chapel Hill who is moving to Redmond to do an internship at Microsoft this summer. In my spring semester, I took Data Mining course for which I had to complete a project as part of the course. After exploring various ideas, I finalized on building a Twitter Sentiment Analyzer. This project aimed to extract tweets about a particular topic from twitter (recency = 1-7 days) and analyze the opinion of tweeples (people who use twitter.com) on this topic as positive, negative or neutral. In this post, I will explain you how you can build such a sentiment analyzer. I will try to explain the concepts without making it sound too technical, but a good knowledge of machine learning classifiers really helps.
Motivation
Twitter is a popular micro blogging service where users create status messages (called “tweets”). These tweets sometimes express opinions about different topics. I propose to build an automatic sentiment (positive or neutral or negative) extractor from a tweet. This is very useful because it allows feedback to be aggregated without manual intervention. Using this analyzer,
Consumers can use sentiment analysis to research products or services before making a purchase. E.g. Kindle
Marketers can use this to research public opinion of their company and products, or to analyze customer satisfaction. E.g. Election Polls
Organizations can also use this to gather critical feedback about problems in newly released products. E.g. Brand Management (Nike, Adidas)
Background
In order to build a sentiment analyzer, first we need to equip ourselves with the right tools and methods. Machine learning is one such tool where people have developed various methods to classify. Classifiers may or may not need training data. In particular, we will deal with the following machine learning classifiers, namely, Naive Bayes Classifier, Maximum Entropy Classifier and Support Vector Machines. All of these classifiers require training data and hence these methods fall under the category of supervised classification.
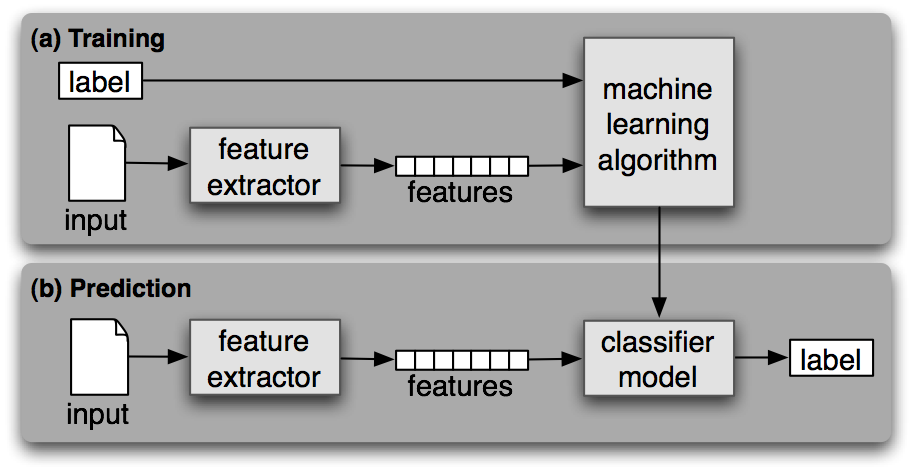
Supervised Classification (Original Source)
To get a good understanding of how these algorithms work, I would suggest you to refer any of the standard machine learning / data mining books. To get a nice overview, you can refer to B. Pang and L. Lee. Opinion mining and sentiment analysis.
Implementation Details
I will be using Python (2.x or 3.x) along with the Natural Language Toolkit (nltk) and libsvm libraries to implement the classifiers. You can use webpy library if you want to build a web interface. If you are using Ubuntu, you can get all of these with a single command as below.
Training the Classifiers
The classifiers need to be trained and to do that, we need to list manually classified tweets. Let's start with 3 positive, 3 neutral and 3 negative tweets.
Positive tweets
@PrincessSuperC Hey Cici sweetheart! Just wanted to let u know I luv u! OH! and will the mixtape drop soon? FANTASY RIDE MAY 5TH!!!!
@Msdebramaye I heard about that contest! Congrats girl!!
UNC!!! NCAA Champs!! Franklin St.: I WAS THERE!! WILD AND CRAZY!!!!!! Nothing like it...EVER http://tinyurl.com/49955t3
Neutral tweets
Do you Share More #jokes #quotes #music #photos or #news #articles on #Facebook or #Twitter?
Good night #Twitter and #TheLegionoftheFallen. 5:45am cimes awfully early!
I just finished a 2.66 mi run with a pace of 11'14"/mi with Nike+ GPS. #nikeplus #makeitcount
Negative tweets
Disappointing day. Attended a car boot sale to raise some funds for the sanctuary, made a total of 88p after the entry fee - sigh
no more taking Irish car bombs with strange Australian women who can drink like rockstars...my head hurts.
Just had some bloodwork done. My arm hurts
As you can see from above, the tweets can have some valuable info about it's sentiment and rest of the words may not really help in determining the sentiment. Therefore, it makes sense to preprocess the tweets.
Preprocess tweets
Lower Case - Convert the tweets to lower case.
URLs - I don't intend to follow the short urls and determine the content of the site, so we can eliminate all of these URLs via regular expression matching or replace with generic word URL.
@username - we can eliminate "@username" via regex matching or replace it with generic word AT_USER.
#hashtag - hash tags can give us some useful information, so it is useful to replace them with the exact same word without the hash. E.g. #nike replaced with 'nike'.
Punctuations and additional white spaces - remove punctuation at the start and ending of the tweets. E.g: ' the day is beautiful! ' replaced with 'the day is beautiful'. It is also helpful to replace multiple whitespaces with a single whitespace
Code - Preprocess tweets
After processing, the same tweets look as below.
Positive tweets
AT_USER hey cici sweetheart! just wanted to let u know i luv u! oh! and will the mixtape drop soon? fantasy ride may 5th!!!!
AT_USER i heard about that contest! congrats girl!!
unc!!! ncaa champs!! franklin st.: i was there!! wild and crazy!!!!!! nothing like it...ever URL
Neutral tweets
do you share more jokes quotes music photos or news articles on facebook or twitter?
good night twitter and thelegionofthefallen. 5:45am cimes awfully early!
i just finished a 2.66 mi run with a pace of 11:14/mi with nike+ gps. nikeplus makeitcount
Negative tweets
disappointing day. attended a car boot sale to raise some funds for the sanctuary, made a total of 88p after the entry fee - sigh
no more taking irish car bombs with strange australian women who can drink like rockstars...my head hurts.
just had some bloodwork done. my arm hurts
Feature Vector
Feature vector is the most important concept in implementing a classifier. A good feature vector directly determines how successful your classifier will be. The feature vector is used to build a model which the classifier learns from the training data and further can be used to classify previously unseen data.
To explain this, I will take a simple example of "gender identification". Male and Female names have some distinctive characteristics. Names ending in a, e and i are likely to be female, while names ending in k, o, r, s and t are likely to be male. So, you can build a classifier based on this model using the ending letter of the names as a feature.
Similarly, in tweets, we can use the presence/absence of words that appear in tweet as features. In the training data, consisting of positive, negative and neutral tweets, we can split each tweet into words and add each word to the feature vector. Some of the words might not have any say in indicating the sentiment of a tweet and hence we can filter them out. Adding individual (single) words to the feature vector is referred to as 'unigrams' approach.
Some of the other feature vectors also add 'bi-grams' in combination with 'unigrams'. For example, 'not good' (bigram) completely changes the sentiment compared to adding 'not' and 'good' individually. Here, for simplicity, we will only consider the unigrams. Before adding the words to the feature vector, we need to preprocess them in order to filter, otherwise, the feature vector will explode.
Filtering tweet words (for feature vector)
Stop words - a, is, the, with etc. The full list of stop words can be found at Stop Word List. These words don't indicate any sentiment and can be removed.
Repeating letters - if you look at the tweets, sometimes people repeat letters to stress the emotion. E.g. hunggrryyy, huuuuuuungry for 'hungry'. We can look for 2 or more repetitive letters in words and replace them by 2 of the same.
Punctuation - we can remove punctuation such as comma, single/double quote, question marks at the start and end of each word. E.g. beautiful!!!!!! replaced with beautiful
Words must start with an alphabet - For simplicity sake, we can remove all those words which don't start with an alphabet. E.g. 15th, 5.34am
Code - Filtering tweet words (for feature vector)
As we process, each of the tweets, we keep adding words to the feature vector and ignoring other words. Let us look at the feature words extracted for the tweets.
Positive Tweets |
Feature Words |
|---|---|
AT_USER hey cici sweetheart! just wanted to let u know i luv u! oh! and will the mixtape drop soon? fantasy ride may 5th!!!! |
'hey', 'cici', 'luv', 'mixtape', 'drop', 'soon', 'fantasy', 'ride' |
AT_USER i heard about that contest! congrats girl!! |
'heard', 'congrats' |
unc!!! ncaa champs!! franklin st.: i was there!! wild and crazy!!!!!! nothing like it...ever URL |
'ncaa', 'franklin', 'wild' |
Neutral Tweets |
Feature Words |
|---|---|
do you share more jokes quotes music photos or news articles on facebook or twitter? |
'share', 'jokes', 'quotes', 'music', 'photos', 'news', 'articles', 'facebook', 'twitter' |
good night twitter and thelegionofthefallen. 5:45am cimes awfully early! |
'night', 'twitter', 'thelegionofthefallen', 'cimes', 'awfully' |
i just finished a 2.66 mi run with a pace of 11:14/mi with nike+ gps. nikeplus makeitcount |
'finished', 'mi', 'run', 'pace', 'gps', 'nikeplus', 'makeitcount' |
Negative Tweets |
Feature Words |
|---|---|
disappointing day. attended a car boot sale to raise some funds for the sanctuary, made a total of 88p after the entry fee - sigh |
'disappointing', 'day', 'attended', 'car', 'boot', 'sale', 'raise', 'funds', 'sanctuary', 'total', 'entry', 'fee', 'sigh' |
no more taking irish car bombs with strange australian women who can drink like rockstars...my head hurts. |
'taking', 'irish', 'car', 'bombs', 'strange', 'australian', 'women', 'drink', 'head', 'hurts' |
just had some bloodwork done. my arm hurts |
'bloodwork', 'arm', 'hurts' |
The entire feature vector will be a combination of each of these feature words. For each tweet, if a feature word is present, we mark it as 1, else marked as 0. Instead of using presence/absence of feature word, you may also use the count of it, but since tweets are just 140 chars, I use 0/1. Now, you can think of each tweet as a bunch of 1s and 0s and based on this pattern, a tweet is labeled as positive, neutral or negative.
Given any new tweet, we need to extract the feature words as above and we get one more pattern of 0s and 1s and based on the model learned, the classifiers predict the tweet sentiment. It's highly essential for you to understand this point and I have to tried to make it as simple as possible. If you don't get how the sentiment is extracted, go re-read from the top or refer a good machine learning / data mining book on classifiers.
In my full implementation, I used the method of distant supervision to obtain a large training dataset. This method is detailed out in Twitter Sentiment Classification using Distant Supervision. For the following sections, I assume that you have a list of large training dataset in CSV or some other format, which you can load and train the classifiers. You can look at below webpages for training datasets.
Let's get the ball rolling
Now that I have covered enough of background information on classifiers, now its time to take a look at Natural Language Toolkit (NLTK) and implement the first two classifiers namely Naive Bayes and Maximum Entropy.
For the explanation, I will use a sample CSV file consisting of labeled tweets, the contents of the CSV file are as below.
sampleTweets.csv
The following code, extracts the tweets and label from the csv file and processes it as outlined above and obtains a feature vector and stores it in a variable called "tweets".
Feature Extraction
Tweets Variable
Our big feature vector now consists of all the feature words extracted from tweets. Let us call this "featureList", now we need to write a method, which gives us the crisp feature vector for all tweets, which we can use to train the classifier.
Feature List
Extract Features Method
Output of Extract Features
Consider a sample tweet "just had some bloodwork done. my arm hurts", the feature words extracted for this tweet is ['bloodwork', 'arm', 'hurts']. If we pass this list as an input to extract_features method which makes use of the 'featureList' , the output obtained is as below.
Bulk Extraction of Features
NLTK has a neat feature which enables to extract features as above in bulk for all the tweets and can be done using the below code snippet. The line of interest is "nltk.classify.apply_features(extract_features, tweets)" where you pass in the tweets variable to the extract_features method.
Both the Naive Bayes and Maximum Entropy Classifier have exactly the same steps until this point and vary slightly from here on.
Naive Bayes Classifier
To explain how a Naive Bayes Classifier works is beyond the scope of this post, having said so, its pretty easy to understand. Refer to the Wikipedia article and read the example to understand how it works. At this point, we have a training set, so all we need to do is instantiate a classifier and classify test tweets. The below code explains how to classify a single tweet using the classifier.
Informative Features
NLTK has a neat feature of printing out the most informative features using the below piece of code.
I highly recommend you to lookup Laurent Luce's brilliant post on digging up the internals of nltk classifier at
Twitter Sentiment Analysis using Python and NLTK.
If you do have a test set of manually labeled data, you can cross verify it via the classifier.
You will soon find that the results are not so good as you expected (see below).
|
testTweet = 'I am so badly hurt'
|
|
processedTestTweet = processTweet(testTweet)
|
|
print NBClassifier.classify(extract_features(getFeatureVector(processedTestTweet)))
|
|
|
|
#Output
|
|
#======
|
|
#positive
|
This is essentially because in the training data didn't cover the words encountered in this tweet and the classifier has little knowledge to classify this tweet and most often the tweet gets assigned the default classification label, in this case happens to be 'positive'. Hence, training dataset is very crucial for the success of these classifiers. Anything below 10k of training tweets will give you pretty mediocre results.
Maximum Entropy Classifier
The explanation of how a maximum entropy classifier works is beyond the scope of this post. You can refer Using Maximum Entropy for Text Classification to get a good idea of how it works. There are a lot of options available when instantiating the Maximum Entropy classifier, all of which are explained at NLTK Maxent Classifier Class documentation. I use the 'General Iterative Scaling' algorithm and usually stick to 10 iterations. You can also extract the most informative features as before which gives a good idea of how the classifier works. The code to instantiate the classifier and to classify tweets is as below.
Support Vector Machines
Support Vector Machines (SVM) is pretty much the standard classifier which is used for any general purpose classification. As the earlier methods, explaining how SVM works will itself take an entire post. Please refer to the Wikipedia article on SVM to understand how it works. I will use the libsvm library (written in C++ and has a python handle) implemented by Chih-Chung Chang and Chih-Jen Lin to instantiate SVM. Detailed documentation of the python handle can be read in the libsvm.tar.gz extracted folder or libsvm github repo.
To make you understand how it works, I will first implement a simple example of classification and extend the same idea to the tweet sentiment classifier.
Consider that you have 3 set of labels (0, 1, 2) and series of 0s and 1s indicate what label they belong too. We will train a LINEAR SVM classifier based on this training data. I will also show how you can save this model for future reuse so that you don't need to train them again. The test data will also comprise of a series of 0s and 1s and now we need to predict the label from the label set = {0, 1, 2}. The below example exactly does what's described in this paragraph.
The output of the above code is as below:-
For the test data, the predicted label was 0 for the first case and 1 for the second case. Internally, the classifier does a cross validation on the training data and outputs the accuracy as 50% which indicates that we need to add more test data to improve the accuracy (given that the results are not totally random!).
Now consider our sampleTweets.csv file, the featureList vector will be as shown below and when we process a sentence, the column values of the unigram features will be set to 1, other wise 0. A combination of these 0s and 1s in the feature vector along with the known label will be the training input to our SVM classifier. It should be noted that the label in the feature vector should be numeric only for the SVM classifier. Hence, I use 0 for positive, 1 for negative and 2 for neutral labels.
The following code shows how to extract the feature vector for the SVM classifier and also the code sample to train and test the SVM classifier.
Phew, I hope you are now armed with the ability to classify the sentiment of any sentence using the above mentioned classifiers. Now, let us talk something about twitter :) !
Retrieving tweets for a particular topic
When you build a twitter sentiment analyzer, the input to your system will be a user enter keyword. Hence, one of the building blocks of this system will be to fetch tweets based on the keyword within a selected time duration.
The most important reference to achieve this is the Twitter API Documentation for Tweet Search. There are a lot of options that you can set in the API query and for the purpose of demonstrating the API, I will use only the simpler options.
The API endpoint I would hit for purpose of demonstration is as below.
|
https://api.twitter.com/1.1/search/tweets.json?q=keyword&lang=en&result_type=recent&count=100&include_entities=0
|
The following code shows how you can retrieve the tweets given a particular keyword. You need to specify config.json
as defined below so that oauth requests can be made.
config.json
get_twitter_data.py
Putting it all together
To summarize, I will brief you on how to connect all the different parts of this tech post.
First, get comfortable with the different classifiers namely Naive Bayes, Maximum Entropy and Support Vector Machines. Learn how they work in the background and the math behind it.
Training data and the features selected for use in the classifier impacts the accuracy of your classifier the most. Look up on the mentioned training data resources already available to train your classifier. I have currently explained how to use unigrams as features, you can include bi-grams, tri-grams and even dictionaries to improve the accuracy of your classifier.
Once you have have a trained model, extract the tweets for a particular keyword. Clean the tweets and run the classifier on it to extract the labels.
Build a simple web interface (webpy) which facilitates the user to enter the keyword and show the result graphically (line chart or column chart using Google Charts)
The source code for the "Twitter Sentiment Analyzer" that I built can be found at https://github.com/ravikiranj/twitter-sentiment-analyzer. Good luck building your twitter sentiment classifier :) !
If you want to tweak and play with Twitter search, check out Twitter REST API Console. Make sure to check oAuth authentication as search API requires authentication.
Comments
Comments powered by Disqus